



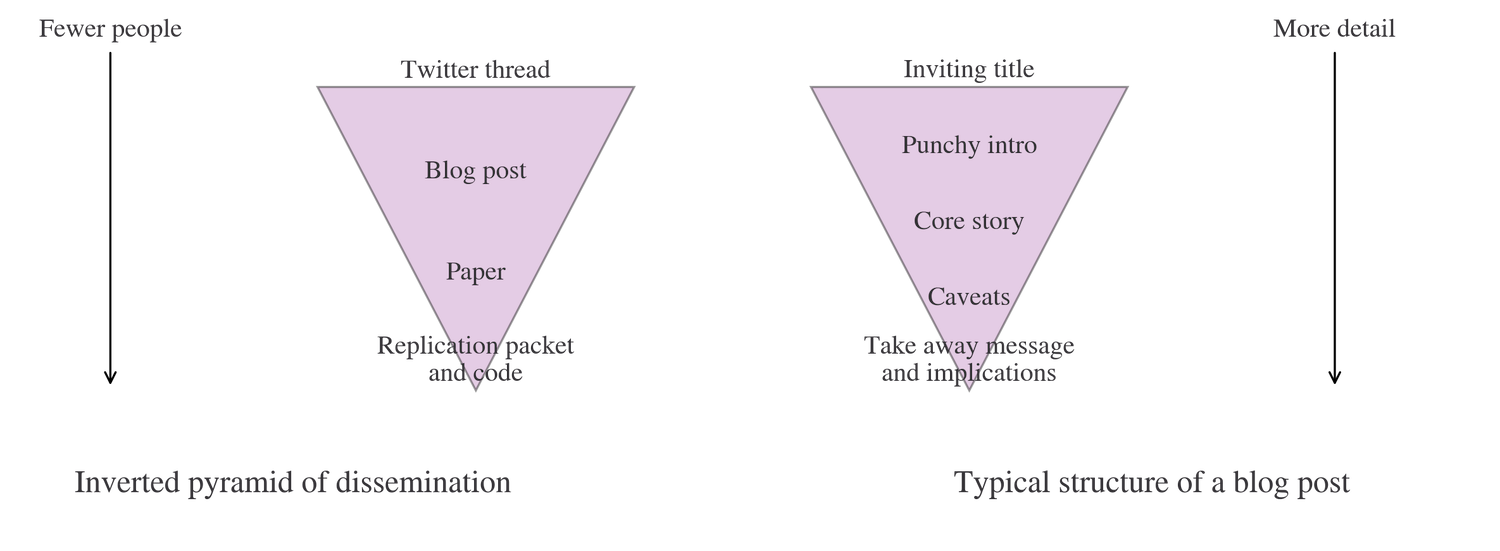
Guest post: Experimenting with Vision AI to recognise digits on an odometer reading from a photo
AI
vision
data science
machine learning
guest post


![]()
![]()









Data science maturity and the cloud
code
python
rstats
data science
cloud
work chat
public sector







No matching items